

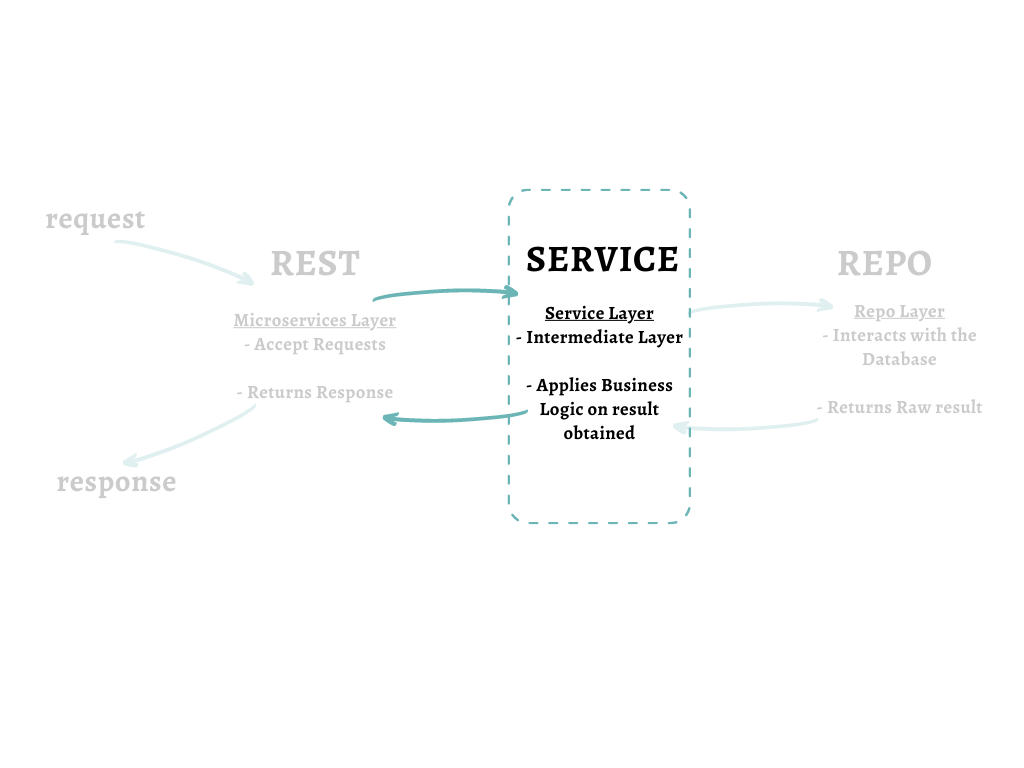
The service layer is where most of the business logic goes in. It acts as an aggregator of data by calling the required repo functions and adds additional logic which may be required to transform the data. In this post, we are going to implement the service layer
If you are still reeling after the last post, let me tell you we are not even halfway there!
We just got done with one layer, i.e. the Repo or the database layer. Well... yes, its true that this layer has most of the logic required but is that the end ? No way! There two more layer layers to go: the Service and the Rest layers. And both of these are equally important to ensure smooth data flow from the user to the application and back.
In Part II, we defined the domain models using structs and interfaces.
In Part III, we implemented those interfaces.
In this post, we use those implemented interfaces. We are going to code out the Service layer....
P.S - We are still using the Category Model as our example candidate
Recap
For the Category model we had defined a struct called Category and an interface called CategoryService which had multiple functions defined in it. We then implemented these functions in the last post under the Repo layer. Let's move on now to the service layer.....
The Service Layer
Repository Structure
Under "internal/petstore" folder, we create a new folder called the "service" folder.
And while you're at it , go ahead and create a file called "category.go" under the service folder since we are using the category model as our example.
.
├── ...
├── internal
│ └── petstore
│ └── service
│ ├── category.go
│ ├── breed.go
│ └── ....
Imports
Next let's sort out the imports required.
The service layer will call the repo layer, which means, we need to import the package for the repo layer ....And maybe alias it like we did for it to be called "db". Oh and we'll also need to import the models package.
So, overall you have something like this:
package service
import (
db "petstore/internal/petstore/repo/postgres"
"petstore/pkg/models"
)The next thing we will do is create variables of the interface and the model type. We'll get to these in a bit.
var cs db.CategoryService
var category db.CategoryCall the Repo Layer
Now for each of our functions in the repo layer, we are going to create corresponding functions in the service layer with the same function signatures.
So, we had a function called "GetAllCategory" in repo, we create the same function here. Now, remember that the repo layer implements the interfaces we defined in the models? The service layer is simply calling this implementation. So, this means, we are calling "GetAllCategory" function from the repo layer inside this function.
That is why we created variables for the CategoryService and Category types from the repo layer earlier. (See the variables "cs" and "category")
Now to call the method all you have to do is this:
cs=&category
cs.GetAllCategory()You initialise the CategoryService variable "cs" with the variable you created for the Category (category) and call all the functions on it using "cs".
So your entire function will look like this
// GetAllCategory : Get all categories.
// Calls respective DB or repo layer
func GetAllCategory() ([]*models.Category, error) {
cs = &category
categories, err := cs.GetAllCategory()
if err != nil {
return nil, err
}
return categories, nil
}For some more clarity, let's look at the CreateCategory function:
//CreateCategory : Create a category. calls respective DB or repo layer
func CreateCategory(c *db.Category) (int, error) {
cs = c
// call repo function
id, err := cs.CreateCategory()
if err != nil {
return id, err
}
return id, nil
}
In this case, you initialise the CategoryService variable "cs" with the parameter value you accept in function because that Category object holds the actual data you want to create. While in the GetAllCategory function, you just passed an empty Category object because you were fetching data.
Similarly, you can call the other functions on the Category model and extend this for other models too. If you get stuck, go ahead and take a look at our GitHub repository.
Why have the Service Layer?
In case you are wondering why did we go to such lengths for creating an entire service layer when we didn't really do much in it other than calling the repo services. Then hold onto that thought.
Our application is still a very simple one and that's why you don't see the significance of the service layer yet. But in reality, the service layer is where most of the business logic goes in.
Lets say, for arguments sake, that when fetching all the categories, like in our example earlier, we want the category name to be converted to upper case and we also want to add a new field for timestamp. In such a case, this customisation on the data returned by the database will be done at the service layer.
This is a very simple example, but in complex applications, there are times where you might need to call multiple functions from the repo layer and combine the data obtained in a particular format before sending it back to the user. That's when the service layer becomes significant. It acts as an aggregator of data by calling the required repo functions and adds additional logic which may be required to transform the data.
In Summary
We have the service layer in place! Simple, wasn't it? Now the only layer remaining is the rest layer. We have to define the routes that will connect back to the service and the repo layer. Before you head to the next post, do head back to the swagger spec we defined in our earlier post and make sure you have Postman. We are going to use these a lot in our upcoming posts. If you're all set, then head to the next post in this series.

Join the conversation