

Databases are ever-present in microservices. In the previous part, we defined domain models. In this post, we will focus on interacting with the database by using the models.
Hmm....So this post is going to be a rather long one..... But rest assured, its quite an interesting one! In this post, we are going to code the "heart" of our application: Database Operations.
Before diving in, a quick recap...
In Part I of this series we created a repository structure. In this you need to remember two paths. The "internal/repo" and the "internal/database" paths.
In Part II, we created our domain models and defined them using Go structs and interfaces. Its now time to implement those interfaces. And we'll be doing just that.
Before diving right in, It'll be good if you know what "layer" we'll be working on. Remember in our previous post, we had defined the three "layers" called the Rest, Service and Repo layer and described how the control flows between them?
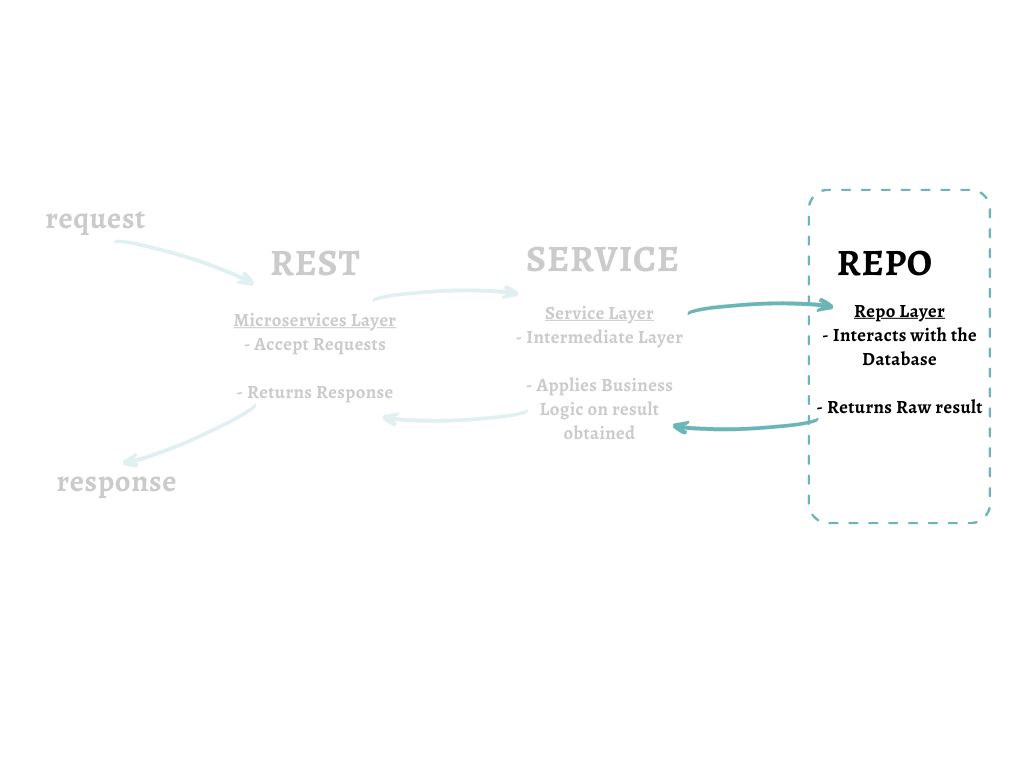
We are going to focus on the Repo layer. That means, in this post, we will connect to a Postgres database and write logic to create, read, update or delete data all in Go.
If you're familiar with PostgreSQL, or any SQL query language, for that fact, you can easily breeze through this post. If not, don't worry! The queries are pretty simple and you can get the hang of it very easily. Let's begin....
Before you Begin : Brush up on the Basics
We'll start simple. For this series, we are using the "sql" package which provides a generic interface for sql databases. In addition, this package requires a database driver specific to the database you are using. For Postgres, the driver we will be using is "lib/pq". Let's go through some basics first :
Connecting to the Database
If you are developing locally, your Postgres instance should be running on localhost and port 5432 (unless you have changed it).
First let's see what imports you'll need:
import (
"database/sql"
"fmt"
//for connecting to db
_ "github.com/lib/pq"
)Make sure that you import "lib/pq" explicitly and alias it as "_". This is because, even though the package is not explicitly used anywhere in the code, it specifies that you'll be using the Postgres driver.
Next, we need a connection URL. And for this we need five values : host (or IP), port, username, password and the name of the database.
const (
host = "localhost" // replace to IP address/domain
port = 5432
user = "postgres" // replace with username
password = "password" // replace with password
dbname = "postgres" // replace with the database name
)Using these, create a connection URL :
//create the connection string
connectionString := fmt.Sprintf("host=%s port=%d user=%s "+
"password=%s dbname=%s sslmode=disable",
host, port, user, password, dbname)Sorted? Now Connect!
var (
DbClient *sql.DB
)
DbClient, err = sql.Open("postgres", connectionString)Executing Queries on the Database
Once you have successfully connected to the database, you are now free to run queries on it. When executing a query using Go, you must know what result the query is going to return. Is it returning one row? multiple rows? or maybe no rows at all..... Depending on this you choose the appropriate function to use.
- One Row --—> QueryRow()
- One or more Rows -—> Query()
- No Rows -—> Exec()
Usually, the "no rows returned" corresponds to a database create, update or delete operation.
That's all great...But how do we piece it together? We'll see this in the context of our application in the next section.
Bring it all together
We are going to use the "category" table as our ideal candidate to perform three main operations on it:
- inserting a record,
- fetching one record
- fetching all the records
1: Get the Repository Ready
Create a subfolder call "postgres" under both "internal/petstore/repo" and the "internal/database" paths. We prefer adding this subfolder with the name of the database instead of directly creating go files inside the repo folder.
Why so? This isolates the logic according to the database allowing flexibility and scalability.
Think of it this way, if in the future, we want to migrate to a newer database, like say, MySQL, we can simply create another subfolder called "mysql". Then, we just replace "postgres" with "mysql" in the imports and our database has changed!
.
├── internal
│ ├── database
│ │ └── postgres
│ │
│ ├── petstore
│ │ └── repo
│ │ └── postgres
│ │
│ └── ...2: Connect to the Database
Our entire code for connecting to the database (that we saw earlier) is going to go under the "/internal/database/postgres" folder in a file called init.go (Although you can give it any name you like). The entire code looks like this:
notice the init() function? In Go, the init function is a function that is first executed when a package is imported somewhere. So when you import the custom "/internal/database/postgres" package, the database connection will be handled automatically.
3: Implement the Interfaces.
If you remember, we defined interfaces in our last post which told us what actions we need to perform on the domain model. For the "Category model", we had three interfaces:
- CreateCategory() (int, error)
Creates a category and return the id or an error - GetCategory(id int) (*Category, error)
Fetch a category based on a given id or return an error - GetAllCategory() ([]*Category, error)
Get all categories or return an error
Our code under the repo/postgres folder will implement these three interfaces. For this, we create a new file called "category.go"
Now, all you have to do is import the "Category" model's struct and interface as a type and use the same function signatures. Something like this:
//Category : import category object from models
type Category models.Category
//CategoryService : import category interface from models
type CategoryService models.CategoryServicefunc (c *Category) CreateCategory() (int, error) {
// ---- Your database logic goes here ----
}
....// Create other functions tooLet's fill in the code in these functions
Insert a Category
According to our API specification, we need to return the category identifier on a successful creation. A raw database query will look like this
INSERT INTO category (category_name) values ($1) RETURNING id;Since we are returning a result in our application, we will have to use the QueryRow() function:
row.Scan() will store the raw result obtained from the query into the appropriate variables, which in our case is the struct defined. You can say we are 'binding' the result to our struct.
In most cases, you don't return anything whenever an insert, update or a delete takes place on the database. In this case, we will use the Prepare() and Exec() functions. Our function will then just return an error in case a failure condition happens or will return nil
Get a Single Category
This is simple. Since we need to fetch one row, the QueryRow() function will suffice here. So the query will be...
SELECT * from category WHERE id=$1;... And The function will look like this:
Notice, that we explicitly type casting the object of Category type to 'models.Category'. This is because our interface defined in the models package returns the "models.Category" type and since we are implementing the interface, we need to adhere types mentioned in the interface definition.
Get all Categories
The query for this might be the easiest one.
SELECT * from category;And we know that this will return multiple rows, we need to use the Query() function here. Something just like this:
There we are done with the interfaces for the Category model! Easy right? If you want to view the entire file, you can find it here.
You can now extend the same thing for implementing other models like the breed, location and pet.
On a Side Note:
If you haven't noticed yet, the "Pet" model depends on the "Category", "Breed" and "Location" Objects. In this, case, we have to execute a join query to fetch the details. For example, say we want to execute a SQL query to get all the pets within a particular category, say dog, the query would look like:
select pet.id,pet.pet_name,
pet.age,pet.description,
pet.category_id,category.category_name,
pet.breed_id,breed.breed_name,
pet.location_id,location.location_name
from pet
inner join category on pet.category_id = category.id
inner join breed on pet.breed_id=breed.id
inner join location on pet.location_id = location.id
where category.categoryName='dog';We have written similar queries for the Pet model. For more reference and viewing the entire code, you can always head over to our GitHub repo .
Summary
Phew! That was a long one. Believe me, we tried to keep it as concise as possible. But this is just the beginning... we got a long road ahead...lot's of concept and code coming your way! So what's next?
In the next post, we implement the remaining two layers, the service and the rest layer. So buckle up and head over to the next part! (Or maybe stay tuned if its still not out yet...)

Join the conversation