

Every application will eventually require a database to persist all the important data. In this post, we'll be designing a simple data model for our application and set up a relational or SQL database (Postgres) for further development.
In our last post we learned how to define APIs with OAS, now we're going to design a database model.
Every application, big or small, will eventually require a database to persist all the important data. No arguments on that one!
It’s pretty evident why decisions related to databases are the most crucial ones when designing any application. In large scale systems, you would not only persist your data in the database, but would also need to ensure that the database is always up, capable of storing or fetching large volumes of data, and is immune to any security breaches. That’s why Database Design and Management is a standalone, super important computer science field!
In this series we won’t go through all the database concepts but we will highlight everything we need to build our application. It’s time to move on to designing a simple data model for storing information related to the app.
To SQL or Not to SQL ?
The variety of databases available today is vast. This is perhaps why choosing the right one is a top priority. Honestly, there's no particular rule for this. Teams usually pick a database depending upon the nature of the data, project's requirements and performance prerequisites.
SQL or relational databases dominate the market and they've been in the game for a long time. Most data can be persisted in a structured and orderly way using tables making them a popular choice.
However, SQL databases tend to have rigid constraints and schemas due to which storing certain data is complex.
This has driven a large number of teams towards NoSQL, for more flexible data persistence. The last few years have seen a rise in the use of NoSQL databases, a powerful alternative to relational databases (Yes! We’ve experienced it first hand).
Selecting a database will depend on the data itself. If you think the data can be stored in a tabular format easily, then SQL is an apt choice. If not, NoSQL it is!

Since SQL is still the obvious choice in the industry and is often used when starting off with simple projects, we'll be using Postgres i.e. SQL as our database in this series.
Don't worry though, a post especially for NoSQL is definitely coming up!
The database design
Let's create a simple data model for our application. First, you need to define the tables (entities) and the relationships between them. Now remember, a lot of concepts, like normalisation, will come into play which might make this post a bit verbose. But since our application is pretty simple, the data model too is an easy one!
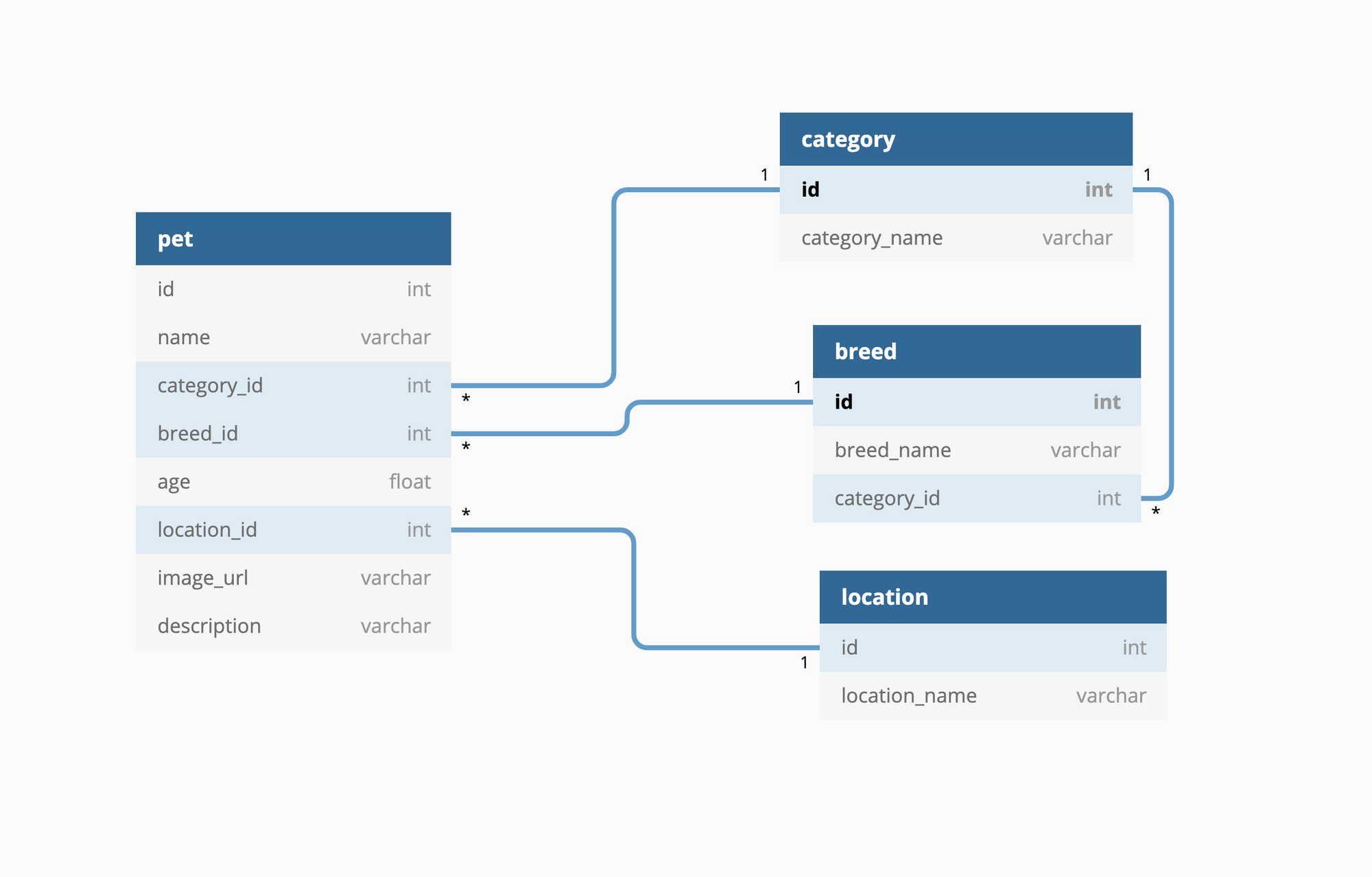
In case you're wondering how we came up with this schema, here’s how we went about designing our database (see above image for reference).
- When creating tables, think about the entities that can exist in the system. In simple terms, think about the domain of the project and find the "nouns" in it. For example, the domain of our project is a pet store, so one entity will be the pet itself.
- Each column in the table will define the attributes of the table. Think of this as the properties or "adjective" of the entity. For us, the pet can have a name, age, and description.
- Now, we know a pet will belong to a category (cat or dog), breed, and location. These are the relationships (search for the "verbs"). This means we will need separate tables for categories, breeds and locations. (Note: A breed also belongs to a category, so that will be a relationship too.)
- Also, notice that one category can have many pets (you can have many dogs or cats). This applies to breeds and locations as well.
- Each table must have a unique identifier, the primary key, so the record can be indexed and identified uniquely.
- The related tables are then linked using foreign keys, which are just references to the primary key of another table (highlighted in blue in the image).
Setting up Postgres and Creating Tables
Install and setup Postgres
Installing Postgres for any particular OS is pretty straightforward. It can be easily installed using a wizard based installer available on the official website. Download the installer and simply follow the steps.
Alternatively, you can run Postgres using Docker (you'll need docker installed for this) by running the command:
docker run --name postgres -e POSTGRES_PASSWORD=password -d -p 5432:5432 postgresP.S. here are the steps to install docker on MacOS, Windows, and Linux.
Create Tables
Connect to the database using a suitable client (Postgres runs on 5432 port) and run this PostgresSQL script.
This will create all the database tables in the "public" schema, which is the default schema. You can also see the ER diagram created:
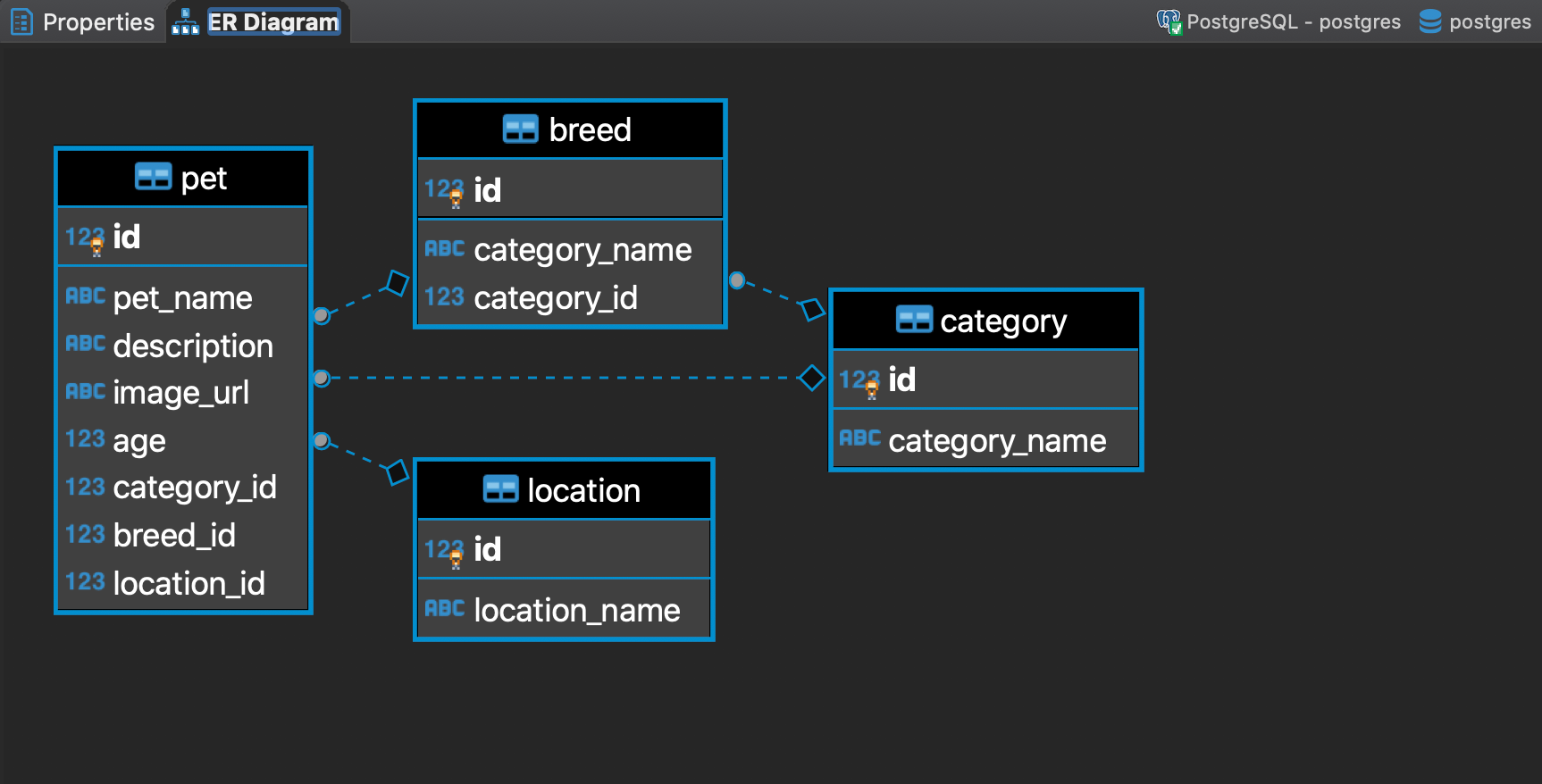
P.S. We run Postgres using Docker and use the DBeaver tool as a client. You’re free to install Postgres locally and use other client tools like pgadmin. We also design the database structure using dbdiagrams.io
In a production grade system, the complexity of the database design is much higher and involves a lot more time and effort to create a scalable database structure. Moreover, a lot of other factors are considered for a database like performance, indexing capabilities, scaling, replication, driver support for a programming language, etc.
Whats Next?
Now that we have the database and API specification in place, we are finally ready to code! Of course, we'll be coding in Go, but before that we need to identify a framework to develop our APIs in.
Our next and final post in this series will go over a few web framework options that are available for API development in Go.
References:



Join the conversation