

Now that Gopher has taught us all about Linked List, let us take a look at a common implementation of Linked List which helps us with many a daily tasks.
LRU Cache
Before we understand how Linked List can be used to achieve LRU Caching we would need to revisit certain basic concepts.
What does Caching mean and why is it so important?
Gopher as you all know is an absolute rockstar when it comes to karaoke nights.One of the main reasons why Gopher is good at it, because unlike a lot of his friends who rely on the lyrics that is being projected on stage Gopher remembers the lyrics of all his songs.The result is that Gopher's perfectly pitched rendition of the song bears an uncanny resemblance to the original.

Gopher's winning strategy: All karaoke sessions that Gopher attends lasts for 60 mins and Gopher get's to sing at least 6 times on a single night.Gopher does the following prior to the night in question:
- Basic research around the genre for that night, what are the current chart-toppers, all time favourites of that genre.
- Memorize the lyrics of 10 such songs.
He can always rely on the lyrics displayed on stage if he runs out of songs, albeit slower it would still work.
If we are to draw a parallel between the karaoke and our caching systems then let's define some of the terms we will be using henceforth:
- Hard Disk Drive - HDD or a Database of some sort - The lyrics displayed on screen which is slower but has all the songs one would ever need.
- Cache - Gopher's memory where he stores lyrics to the songs that he will sing that night.
- Server - Gopher himself.
- Client - All his friends in the audience.
To summarise, when a user makes an api call to a server to view the information on a particular website the server fetches the information from it's storage(hard disk drive - HDD or a Database of some sort) and responds to this api request.The web browser on the user's end receives this data and then paints the information on the browser for the user to view.
Now this setup works for a small set of users, but as we scale to a larger pool of users the server will take time to respond to numerous user api requests as reading data from a HDD is a slow process.
Caching to the rescue!
In order to speed things up if we were to load up this information in memory of the server then the api responses will be a lot of quicker.This is knows a Cache.
I know what you are thinking, but wouldn't this be a duplication of data and wouldn't it increase my infrastructure costs and make my server slower still?
Not quite!
A cache is just a high speed data storage layer which stores a small amount of data temporarily so that all future api requests for this small amount of data gets a faster response because we don't have to read the same from a Hard Disk Drive(HDD).
One of the major hurdles of this layer is that since it only stores a subset of the actual data and because the space available for storage is limited, we need to have a robust policy in place which determines what data is to be cached and what has to be purged. It is also worth noting that we will need to access the slower storage(HDD) from time to time when the Cache doesn't hold the information we are looking for. One such policy is called an LRU or Least Recently Used Caching Mechanism.
What is LRU Caching ?
LRU Caching is an efficient way of caching data in memory where the cache data structure(Doubly Linked List) automatically evicts it's Least Recently Used items when the cache is full.
How is LRU Caching Implemented?
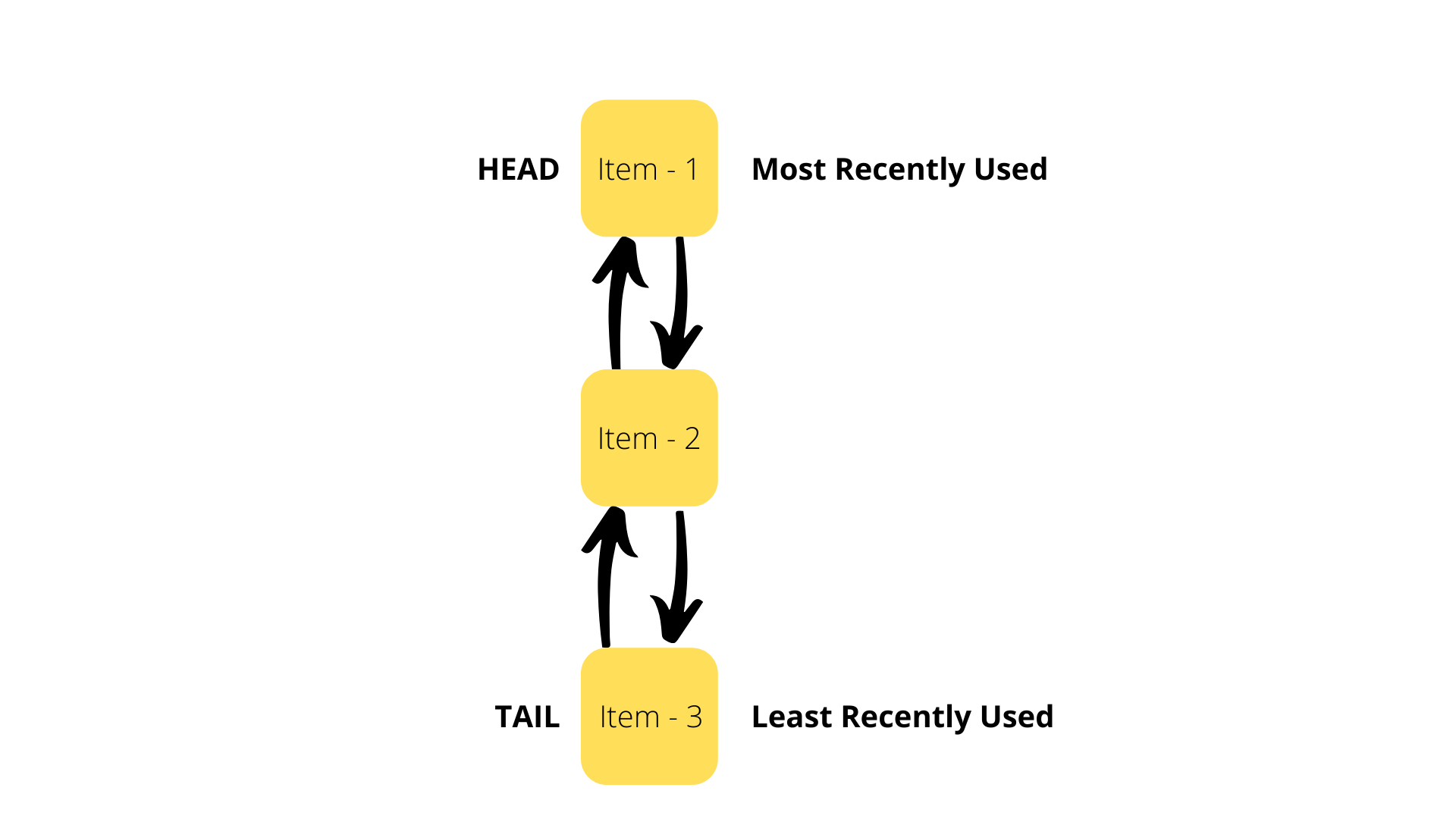
An LRU Cache is built using two data structures: a Doubly Linked List and a Hash Table.
The Doubly Linked List is setup with its Head as the Most Recently Used item and its Tail as the Least-Recently Used item.
This allows the system to access the Least Recently Used element in O(1) time complexity by accessing the Tail of the Doubly Linked List.
As shown in the previous blog on Doubly Linked Lists, finding an item in a Doubly Linked List takes O(n) time where 'n' stands for the number of elements in the Doubly Linked List.So then how do we make sure we have quick look up's in a Caching system using Doubly Linked List's?
The solution to this is to use Hash Table's which are known for their quick lookup capabilities. The Hash Table will map each item in the Map to a node in the Doubly Linked List. This lets us find an element in our Doubly Linked List in O(1) time, instead of O(n).
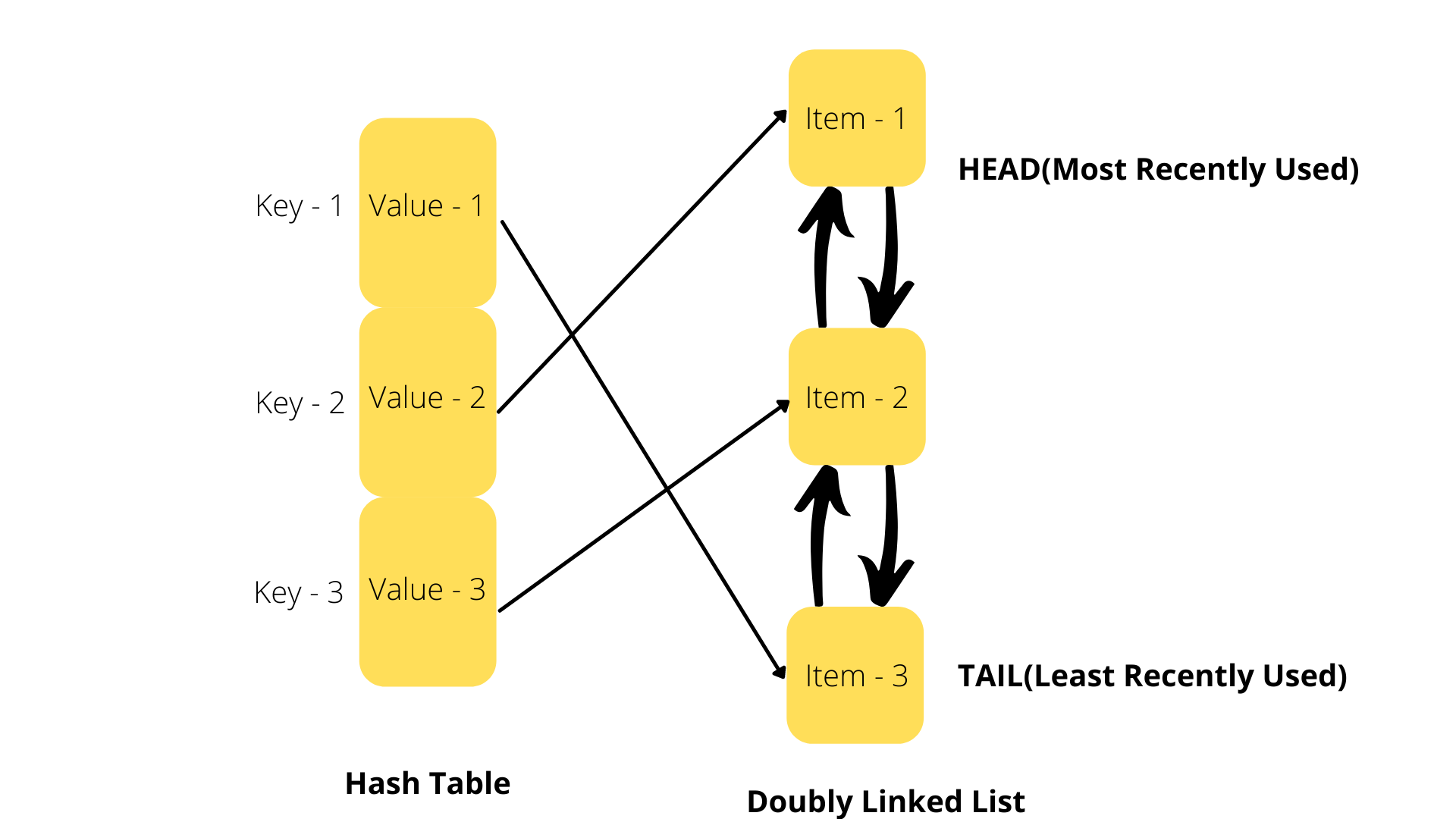
Accessing & Evicting Data from an LRU Cache:
Let us go ahead and list down the series of steps which we will go through every time we need to access an item from the Cache:
-
Search for an item in the Hash Table
-
If the item is present in the Hash Table then it's called a Cache hit.In this case we do the following steps:
- Use the Hash Table to find the corresponding Node in our Doubly Linked List
- Move this item's Node as the Head of the Doubly Linked List as it has been accessed recently.
-
If the item is not present in the Hash Table then it's called a Cache Miss and we need load this item into Cache.In order to do this we follow the following steps:
- Check the size of our Cache and if it's full then we need to evict the Least Recently Used(LRU) item from our Doubly Linked List,i.e, the tail of our Doubly Linked List.
- We not only have to evict the item from the Doubly Linked List but also from our Hash Table so that no space remains allocated to this item in our Cache.
- Next we create a new Node in the Doubly Linked List for the new item which we fetched from our HDD or Database.We insert this Node at the Head of the Doubly Linked List.We also add this item into our Hash Table with Node as the value.
Please note that even with all these steps the system is able to update the cache and retrieve the element in an O(1) time.
With this I hope you have a fair understanding of Linked List Data Structure and it's practical uses.Now we need to follow Gopher on his next adventure to learn about our next data structure.
P.S: The next data structure has a lot to do with school.Stay Tuned!

Join the conversation